En esta lección se estudian los distintos tipos de variables estadísticas (numéricas y categóricas) y se introducen los conceptos de asociación, independencia y variables explicativa y respuesta.
Figura 1: Ilustración utilizada con fines educativos. Fuente: USF ClipArt Collection (University of South Florida).
1 Tipos de variables: una clasificación fundamental
En estadística, entender la naturaleza de las variables es el primer paso para elegir el análisis correcto. Las variables se clasifican en dos grandes familias: numéricas y categóricas.
1.1 Variables numéricas
Pueden tomar un rango amplio de valores numéricos y tiene sentido realizar operaciones como sumar, restar o calcular promedios con ellos.
Continuas: Pueden tomar cualquier valor en un intervalo (ej: tasa_desempleo, ingreso_mediano_hogar, la altura de una persona).
Discretas: Solo pueden tomar valores enteros que representan conteos (ej: poblacion_total, número de hijos, cantidad de viviendas).
Importante: No todo lo que parece número es una variable numérica en el sentido estadístico. Un número de teléfono, un RUT o un código postal son identificadores, no tiene sentido calcular su promedio. Son, en realidad, categóricas nominales.
1.2 Variables categóricas
Clasifican a los individuos en categorías.
Nominales: Las categorías no tienen un orden inherente. No se puede decir que una sea “mayor” que otra (ej: region, sexo, religión).
Ordinales: Las categorías tienen un orden natural, aunque la distancia entre ellas no sea cuantificable (ej: nivel_educacional con niveles “básica”, “media”, “superior”; o la respuesta a una encuesta con “muy malo”, “malo”, “regular”, “bueno”, “muy bueno”; o un rango como el que posee un uniformado: “cabo”, “sargento”, “capitán”).
Para simplificar, muchos análisis tratan las ordinales como nominales, pero es importante reconocer su orden.
2 Relaciones entre variables
Una vez que entendemos los tipos de variables, podemos empezar a preguntarnos cómo se relacionan entre sí. Gran parte de la estadística busca responder preguntas como: ¿Están relacionadas estas dos variables? ¿Una afecta a la otra?
2.1 Asociación entre variables
Decimos que dos variables están asociadas (o son dependientes) cuando los valores de una tienden a variar de forma sistemática con los valores de la otra. En caso contrario, se dice que son independientes.
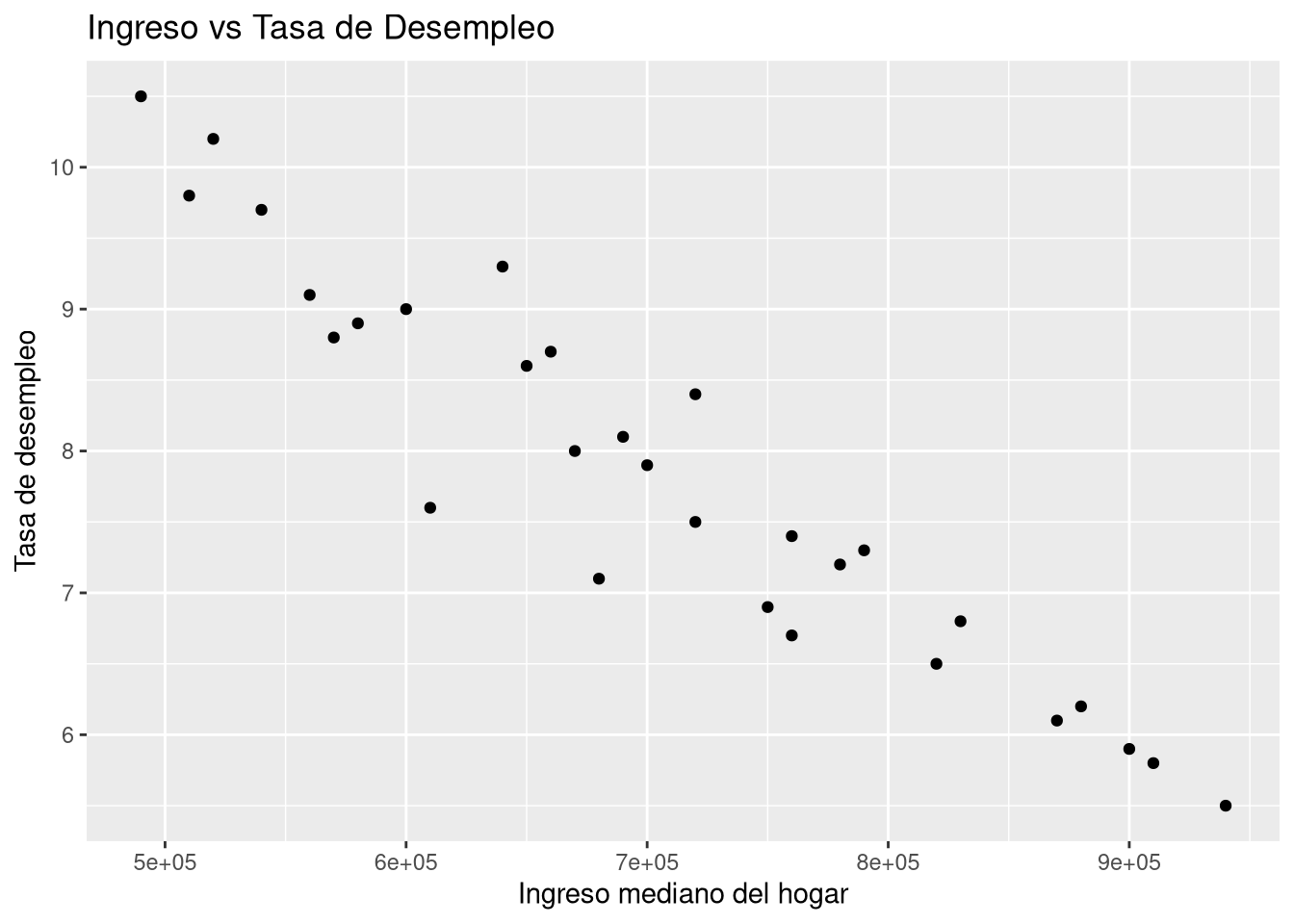
Asociación positiva: Cuando una variable aumenta, la otra también tiende a aumentar. Por ejemplo, en el estudio de OpenIntro, se observa que las ciudades con mayor ingreso medio tienden a tener mayor crecimiento poblacional.
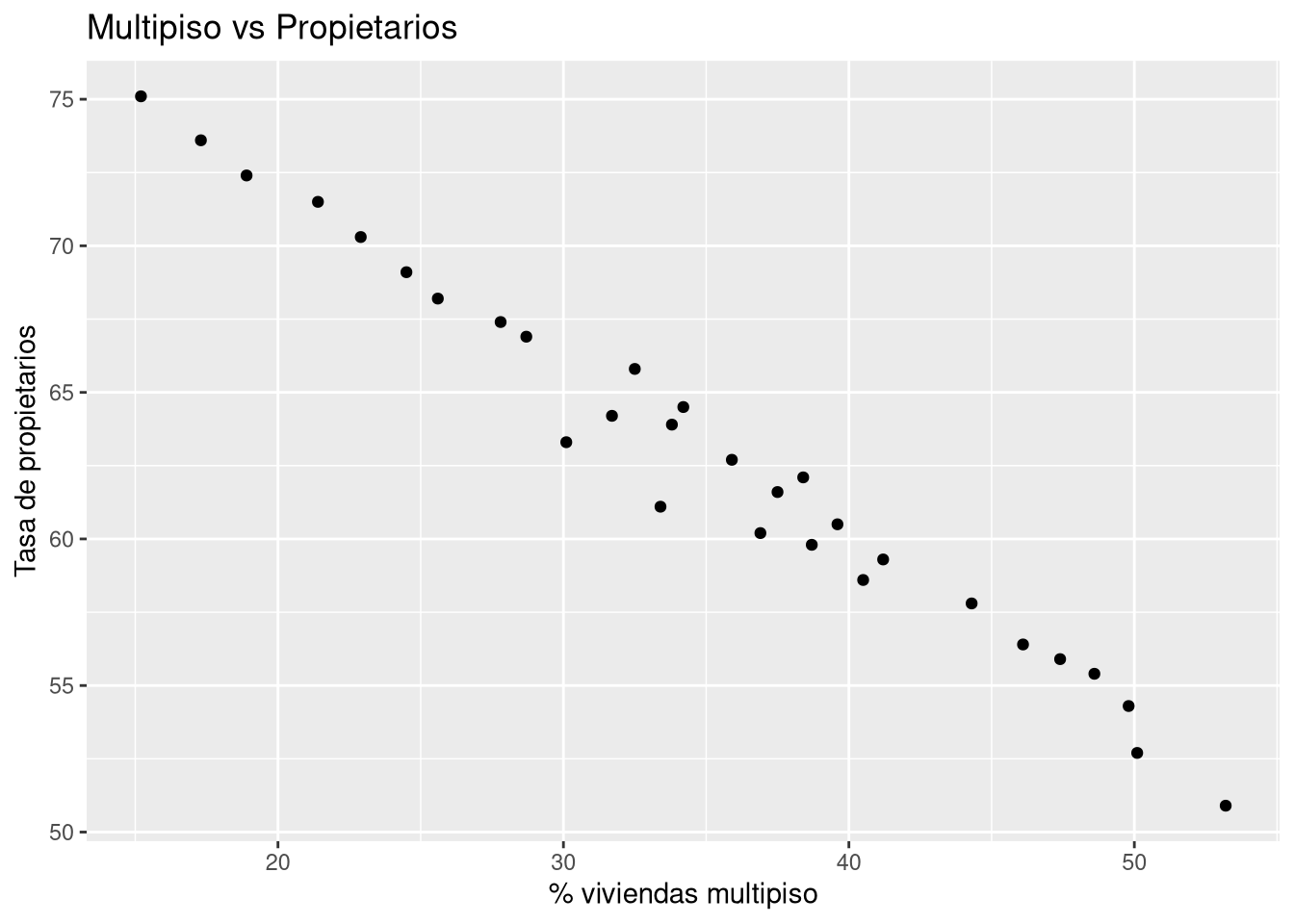
Asociación negativa: Cuando una variable aumenta, la otra tiende a disminuir. Por ejemplo, condados con más viviendas en edificios de varios pisos (multipiso) tienden a tener tasas de propietarios más bajas.
Ejemplo con tus datos de region30 (lo veremos en la práctica): Exploraremos si existe asociación entre ingreso_mediano_hogar y tasa_desempleo. ¿Será positiva o negativa?
2.2 Variables explicativas y de respuesta
Cuando sospechamos que una variable podría influir o causar un cambio en otra, etiquetamos a la primera como variable explicativa (o independiente) y a la segunda como variable respuesta (o dependiente).
Por ejemplo, en el estudio de los stents de la Lección 1: - Variable explicativa: El grupo al que pertenece el paciente (tratamiento con stent o control). Es lo que se manipula o estudia como posible causa. - Variable respuesta: Si el paciente sufrió o no un ACV. Es el resultado que se mide.
Importante: Etiquetar las variables de esta manera es una hipótesis del investigador. No garantiza que exista una relación causal. Para probar la causalidad, se necesita un experimento.
3 ¿Cómo obtenemos evidencia? Estudios observacionales y experimentos
La forma en que recolectamos los datos determina qué tipo de conclusiones podemos sacar.
Estudio observacional: Los investigadores observan y miden variables sin intervenir ni manipular el entorno. Simplemente registran lo que ocurre. Este tipo de estudio puede identificar asociaciones, pero no puede establecer causalidad. Por ejemplo, observar que las personas que hacen ejercicio viven más no prueba que el ejercicio cause una mayor longevidad; podría haber otros factores (como la dieta o la genética) que influyan.
Experimento: Los investigadores asignan activamente un tratamiento a los sujetos. La herramienta clave es la asignación aleatoria (al azar) de los sujetos a los grupos. Esto ayuda a equilibrar otros factores que podrían influir en el resultado, de modo que cualquier diferencia en la respuesta se pueda atribuir al tratamiento.
Grupo de control: Recibe un placebo o ningún tratamiento. Sirve como línea de base para comparar.
Placebo: Una sustancia o tratamiento sin el principio activo (ej. una pastilla de azúcar). Sirve para controlar el efecto psicológico de creer que se está recibiendo un tratamiento.
El caso de los stents (Lección 1) es un ejemplo perfecto de experimento aleatorio. Los pacientes fueron asignados al azar a los grupos de tratamiento y control. Esto permitió a los investigadores concluir (de forma sólida) que los stents, lejos de ayudar, parecían causar daño. Sin la asignación aleatoria, no podrían haber hecho esa afirmación causal.
Regla de oro:Asociación no implica causalidad. Solo un experimento aleatorio puede proporcionar evidencia sólida de una relación causal.
Advertencia
Los datos utilizados en esta lección (region30) corresponden a una versión didáctica simplificada de la data county (openintro) que simula indicadores regionales en Chile. No representan datos oficiales del INE ni de ningún organismo público, y han sido construidos únicamente con fines pedagógicos para el estudio de tipos de variables y relaciones estadísticas.
4 Cargar librerías y explorar los datos
Cargamos tidyverse (colección de paquetes para ciencia de datos) y leemos el archivo region30.csv. Luego usamos glimpse() para ver la estructura de los datos de forma compacta.
pueden tomar cualquier valor en un intervalo (ej: tasa_desempleo).
Numéricas discretas
toman valores enteros que representan conteos (ej: poblacion_total).
Categóricas nominales
categorías sin orden (ej: region).
Categóricas ordinales
categorías con un orden natural (ej: nivel_educativo).
Pero cuidado: no todo lo que parece número es una variable numérica en sentido estadístico. Por ejemplo, un número de teléfono es un identificador, no tiene sentido calcular su promedio. En cambio, la tasa_desempleo sí es una variable numérica con la que podemos hacer operaciones.
Para las variables categóricas, podemos usar table() o count() para ver frecuencias. Por ejemplo, la variable region:
Cuando queremos explorar la relación entre dos variables numéricas, el gráfico adecuado es el diagrama de dispersión (scatter plot). Veamos si existe relación entre el ingreso mediano del hogar y la tasa de desempleo:
ggplot(region30, aes(x = ingreso_mediano_hogar, y = tasa_desempleo)) +geom_point() +labs(x ="Ingreso mediano del hogar", y ="Tasa de desempleo",title ="Ingreso vs Tasa de Desempleo")
¿Se observa alguna tendencia? ¿A mayor ingreso, menor desempleo?
Ahora exploremos otra posible relación: porcentaje de viviendas en edificios de varios pisos versus tasa de propietarios.
ggplot(region30, aes(x = viviendas_multipiso, y = tasa_propietarios)) +geom_point() +labs(x ="% viviendas multipiso", y ="Tasa de propietarios",title ="Multipiso vs Propietarios")
Importante: Que dos variables muestren una asociación en un gráfico no significa que una cause la otra. La correlación no implica causalidad.
6 Efecto de los valores atípicos (outliers) en la media y la mediana
Vamos a simular un conjunto de ingresos para entender cómo los valores extremos afectan las medidas de tendencia central.
Primero, generamos 60 ingresos “típicos” usando una distribución log-normal (común para ingresos) y luego añadimos tres valores extremadamente altos.
set.seed(123) # para que los resultados sean reproduciblesingresos_tipicos <-round(rlnorm(60, meanlog =log(650), sdlog =0.25))ingresos_extremos <-c(5000, 7000, 12000)ingresos <-c(ingresos_tipicos, ingresos_extremos)
Ahora tenemos 63 valores. Veamos un resumen estadístico:
length(ingresos)
[1] 63
summary(ingresos)
Min. 1st Qu. Median Mean 3rd Qu. Max.
398 578 668 1027 794 12000
Calculamos la media y la mediana:
media <-mean(ingresos)mediana <-median(ingresos)media
[1] 1026.524
mediana
[1] 668
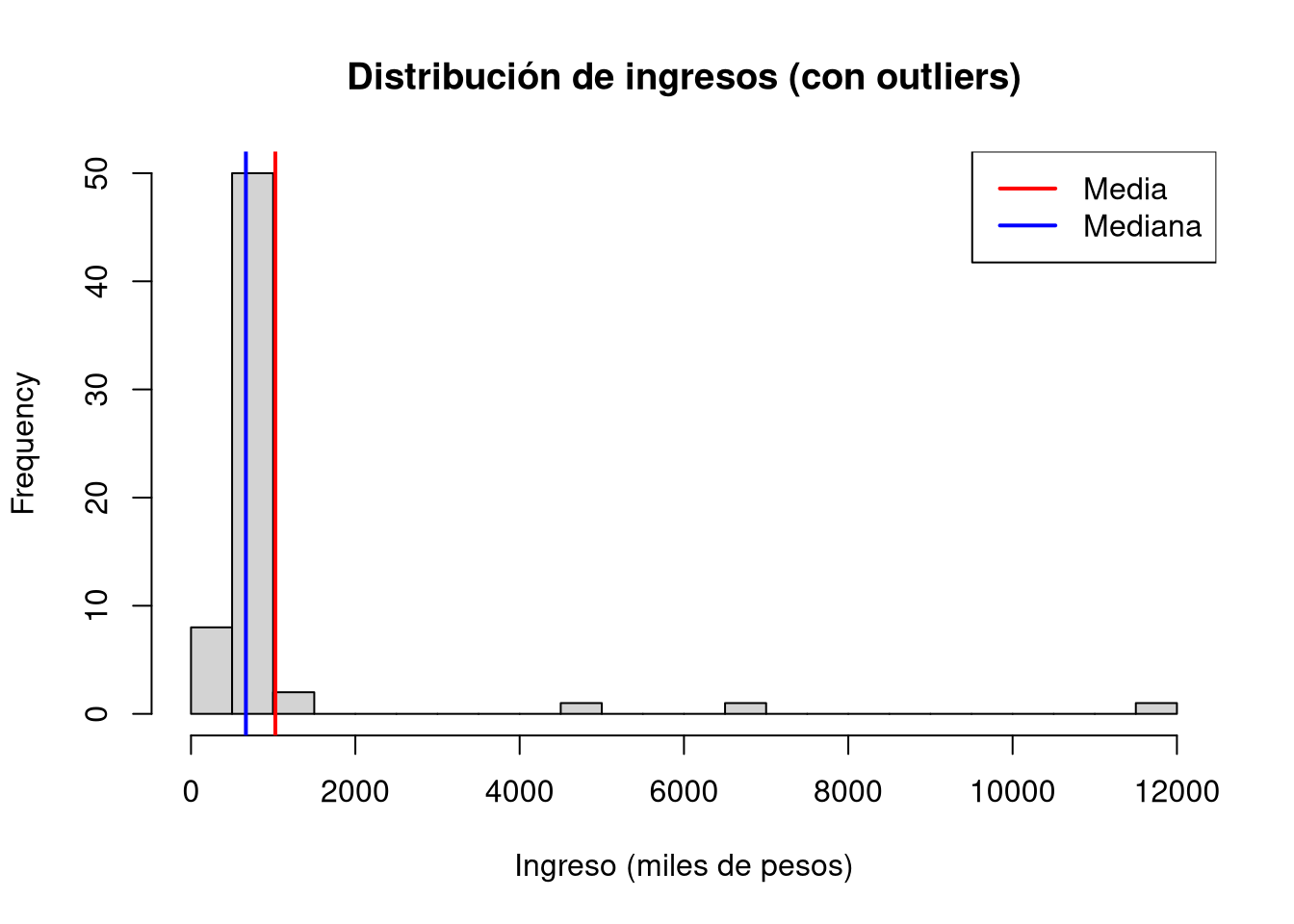
Observa que la media es mucho mayor que la mediana debido a los valores extremos. Visualicemos la distribución con un histograma:
hist(ingresos, breaks =20, main ="Distribución de ingresos (con outliers)",xlab ="Ingreso (miles de pesos)")abline(v = media, col ="red", lwd =2)abline(v = mediana, col ="blue", lwd =2)legend("topright", legend =c("Media", "Mediana"), col =c("red", "blue"), lwd =2)
La media es sensible a outliers; la mediana es más robusta. Si eliminamos los valores extremos:
A continuación, se presentan tres estudios reales. Para cada uno, intenta identificar la pregunta de investigación, los sujetos involucrados y las variables, clasificándolas según su tipo. Puedes usar estos ejemplos para discutir en clase o como ejercicios individuales.
Contaminación del aire y partos prematuros
Los investigadores recolectaron datos para examinar la relación entre contaminantes atmosféricos y partos prematuros en el sur de California. Durante el estudio, los niveles de contaminación se midieron mediante estaciones de monitoreo de calidad del aire. Específicamente, se registraron niveles de monóxido de carbono en partes por millón, dióxido de nitrógeno y ozono en partes por cien millones, y material particulado grueso (\(PM_{10}\)) en \(\frac{\mu g}{m^{3}}\). Se recopilaron datos de la duración de la gestación de 143.196 nacimientos entre los años 1989 y 1993, y se calculó la exposición a la contaminación durante la gestación para cada nacimiento. El análisis sugirió que el aumento de \(PM_{10}\) y, en menor grado, las concentraciones de CO podrían estar asociados con la ocurrencia de partos prematuros.
Identifica la pregunta principal de investigación del estudio.
¿Quiénes son los sujetos en este estudio y cuántos se incluyeron?
¿Cuáles son las variables en el estudio? Identifica cada variable como numérica o categórica. Si es numérica, indica si es discreta o continua. Si es categórica, indica si es ordinal.
El método Buteyko
El método Buteyko es una técnica de respiración superficial desarrollada por el médico ruso Konstantin Buteyko en 1952. La evidencia anecdótica sugiere que el método Buteyko puede reducir los síntomas del asma y mejorar la calidad de vida. En un estudio científico para determinar la efectividad de este método, los investigadores reclutaron a 600 pacientes asmáticos de entre 18 y 69 años que dependían de medicamentos para el tratamiento del asma. Estos pacientes se dividieron aleatoriamente en dos grupos: uno practicó el método Buteyko y el otro no. Los pacientes fueron evaluados en una escala del 0 al 10 en cuanto a calidad de vida, actividad, síntomas de asma y reducción de medicación. En promedio, los participantes del grupo Buteyko experimentaron una reducción significativa de los síntomas de asma y una mejora en la calidad de vida.
Identifica la pregunta principal de investigación del estudio.
¿Quiénes son los sujetos en este estudio y cuántos se incluyeron?
¿Cuáles son las variables en el estudio? Identifica cada variable como numérica o categórica. Si es numérica, indica si es discreta o continua. Si es categórica, indica si es ordinal.
Tramposos
Investigadores que estudiaban la relación entre la honestidad, la edad y el autocontrol realizaron un experimento con 160 niños de entre 5 y 15 años. Los participantes informaron su edad, sexo y si eran hijos únicos o no. Los investigadores pidieron a cada niño que lanzara una moneda en privado y que registrara el resultado (blanco o negro) en una hoja de papel, y les dijeron que solo recompensarían a los niños que reportaran “blanco”. Los hallazgos del estudio se pueden resumir así: “A la mitad de los estudiantes se les dijo explícitamente que no hicieran trampa y a la otra mitad no se les dio ninguna instrucción explícita. En el grupo sin instrucciones, la probabilidad de hacer trampa fue uniforme en todos los grupos según las características del niño. En el grupo al que se le dijo explícitamente que no hiciera trampa, las niñas tenían menos probabilidades de hacer trampa, y mientras que la tasa de trampa no variaba con la edad en los niños, disminuía con la edad en las niñas”.
Identifica la pregunta principal de investigación del estudio.
¿Quiénes son los sujetos en este estudio y cuántos se incluyeron?
¿Cuántas variables se registraron para cada sujeto en el estudio para poder llegar a estas conclusiones? Indica las variables y sus tipos.
Clasifica las siguientes variables de region30. Para cada una, indica si es: numérica continua, numérica discreta, categórica nominal o categórica ordinal, y justifica brevemente.
Variable
Tipo
Justificación
Explorando la variable region. Al usar glimpse(region30) no se ven todos los valores de la variable region. ¿Qué comando usarías para listar todos los valores únicos de esa variable?
Tip
(Ayuda: prueba con unique(), sort(), table() o combinaciones)
# Escribe aquí tu código
Interpretación de gráficos. Observa el gráfico de dispersión entre viviendas_multipiso y tasa_propietarios. ¿Qué tendencia parece haber? ¿Crees que vivir en un edificio de varios pisos causa una menor tasa de propietarios? Explica.
Media vs mediana. En el ejemplo de los ingresos simulados, ¿por qué la media es mayor que la mediana? ¿Qué medida es más representativa del “ingreso típico” en presencia de outliers? ¿Por qué?